
LibParlor is pleased to publish this post by Samuel as our first LibParlor-HLS crossover post. Don’t miss our post over at HLS this week, written by our LibParlor Contributing Editors Suzy Wilson and Paige Sundstrom!
Samuel Hansen is a iSchool student at the University of Wisconsin, Madison studying to become a mathematics librarian. They are also the producer of the mathematics podcast Relatively Prime and developer for the PodcastRE archive of podcasts. In their rare free time you will find them riding bikes, cheering on Arsenal, and making decaf pour overs. You can find out more about Samuel by visiting their personal website and you can read more of Samuel’s thoughts about Libraries and Information at Hack Library School or about mathematics at The Aperiodical and Second-Rate Minds.
*The author wishes to thank Zachary Fanin and Shane Wolfram for the important role they played as the author’s fellow group members in the research about to be discussed*
IntroductionIntroduction The start of a research article providing background information and an overview of the research presented in the article.
It was just a class assignment. Not even that crazy of an assignment. All we were supposed to do was take a research question we already had some knowledge in and apply some digital humanities tools to it. My group members would have been well served to have not allowed me to choose our direction, but I can be rather convincing when I want to be, and so we decided/I harangued them into exploring the world of mathematical literature classification. Specifically, we were going to investigate the citation network created when instead of linking together authors we link together the Mathematical Subject Classifications (MSC) value, the dominant topic classification system in mathematics, of a paper with the MSC value of the papers it cites.
Sure this was a rather ambitious project to take on, but I was completely confident in our ability to generate these networks as soon as we had the data we needed. However, we never got a chance to test this hypothesis because try as hard as we might we never even came close to getting the data we needed because we could not convince the organization that held it to respond to our requests. After over a month of trying it became clear we were not going to be able to complete the project we had planned on. We needed a new plan, and fast. In the end, it was the nature of our failure that illuminated the way forward. We wanted the topics of mathematical papers, and if they were not willing to give them to us, then we had no choice but to try and make our own. Or in other words, we decided to try our hand at mathematical topic modeling.
Our process
Of course, in order to do topic modeling we needed mathematical papers and a lot of them. After having already failed once to get data we were worried about hitting the same wall a second time. Thankfully our professor suggested a potential source for papers, a group from the University of Wisconsin called GeoDeepDive who help supply large amounts of full-text journal articles for research purposes (They are actively looking for research partners with project ideas that require the text of journal articles). While GeoDeepDive did not have any mathematical papers in their database when we first talked to them, they said as long as we provided them with journal titles they would provide us with articles. Within a couple of weeks, GeoDeepDive had developed a corpus of 22,397 mathematics article for us to work with (Thank you, Ian Ross).
22,397 full-text mathematical papers is an enormous amount of text for a group of students to be attempting to topic model. Thankfully we had help from the wonderful Center for High Throughput Computing at the University of Wisconsin, who provides large-scale computing resources to any faculty, researcher, staff, or student. The Center ran our topic model for us six times, each one taking nearly 20 hours to complete and using a different random ⅓ sample of our corpus as a training set.
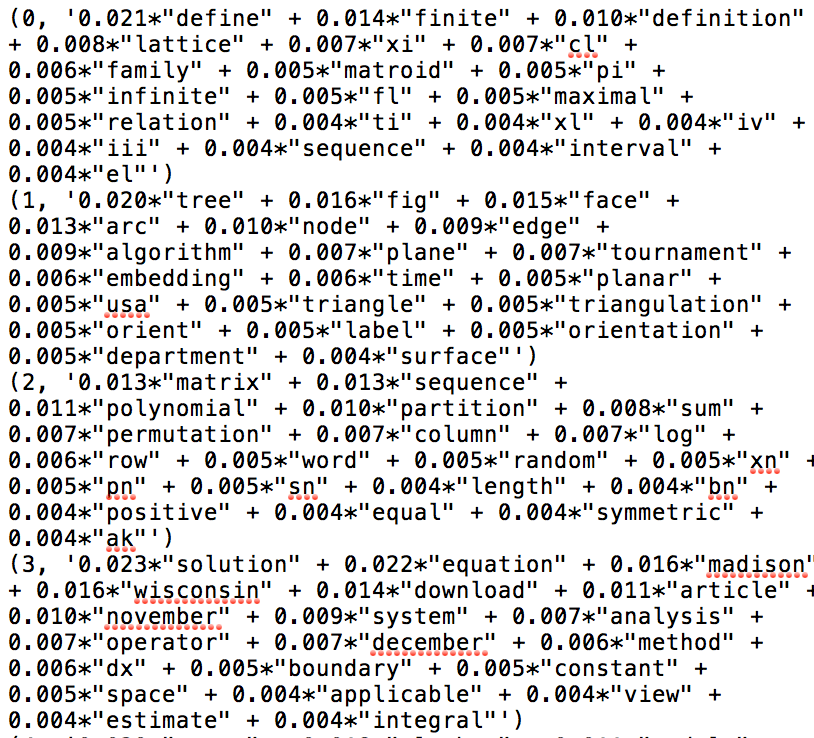

After the topic modeling was finished, we received a whole load of text files. Six of the text files provided the topics generated for each run;these files consisted of 10 topics made up of 20 words. The rest of the text files were filled with the percentages of each topic the model assigned to an article. These files consisted of an article’s id followed by ordered pairs of topic number and the percentage that topic represented the contents of the article. It did not take much examination to realize we were not likely going to be getting the resultsResults The section of a research article where researchers share the results from the research. This section takes the results and directly connects them to the research questions or hypotheses posed at the start of the article. Also can be called “Findings.” had hoped for.
For example, each run of the topic modeling had created at least one topic which was just made up of gibberish words like est, le, and ci. We were able to determine this was due to issues surrounding trying to machine read mathematical typesetting. This was bothersome, but not the end of the world as we figured we would just be able to throw these results out without affecting our other results. Much more worrisome were the mathematical words the modeling had used to populate the topics. These were words like map, proposition, complex, equivalence, and space – all mathematical words to be sure, but not ones which were specific to any one subject within mathematics. We tried to code these, going through and assigning them a mathematical subject if they were specific to one. Of the 1,200 words that made up our topics, we were only able to code 333 of them, with Graph Theory and Algebra being the most common. Graph theory, in particular, stood out, because unlike Number Theory, Analysis, or even Algebra, Graph Theory words were often clustered together into single topics meaning that the topic model seemed to be more accurately identifying them as related concepts.
Our failure to assign meaningful codes to the topic words led directly to our next failure, that of classifying the papers themselves. With so many words coded as “Undefined,” it inevitably dominated our classification attempt. For our analysis, we added together the percentage values for each code by paper. For the 88,058 article topic model attempts the highest value code was Undefined for 73,881 of them. In fact, only one other code ever became the highest value, and that was Graph Theory. As far as the second highest value when Undefined was the highest, 40,549 had Graph Theory assigned as the second highest code, 26,696 were assigned Algebra, and the remaining 6,636 were assigned Set Theory, Analysis, or Number Theory.


Clearly, our topic modeling was not going to be useful for assigning topics to mathematical papers in general, but it did seem to us that it may just be helpful at identifying which papers were about Graph Theory. In order to test this hypothesis we managed to get MSC values for 2,981 of the papers in our corpus. Our analysis of those papers determined that our topic modeling could either almost never assign Graph Theory to a non-Graph Theory paper but it would then miss assigning Graph Theory to a lot of papers which were about the topic or it could manage to assign Graph Theory to nearly every paper which was about it as well as a whole load that were not. So it is fair to say, the topic modeling did not even lead to useful results in identifying Graph Theory papers.


Lessons learned
“We finished this project knowing the dangers of relying on data that is not already on hand. We also learned the importance of leveraging existing resources.”
For those of you keeping track that leaves the list of failures in this project as failure to get data, failure to code topics, failure to classify mathematical articles generally, and failure to classify Graph Theory articles specifically. That is a long list of failures, and a list I am very happy about. You always hear about how failure is a much better teacher than success, and though it is a cliche, in this case, it was very true. We finished this project knowing the dangers of relying on data that is not already on hand. We also learned the importance of leveraging existing resources. While we did not classify mathematical articles, we did definitively answer the question of whether naive topic modeling could do so with a resounding no. We also noticed that there seems to be something unique about the language of Graph Theory. We hypothesize that it is likely due to the relatively young nature of the discipline, which could be an interesting area to study in the future. More than anything though, we learned that we could take on a way overly ambitious project and see it through to the end. Sure we failed over and over and over again, but each time led to an important lesson or an interesting new question. And really, what else can anyone really ask for from research than that, especially some students just trying to do a class assignment?
Featured image of the Cutter Mathematics Collection at the University of Wisconsin, Madison Kleene Mathematics Library, taken by the author.

This work is licensed under a Creative Commons Attribution 4.0 International License
The expressions of writer do not reflect anyone’s views but their own
0 comments on “1+1=3? Or How to fail at every step and still get a result”